DeepSeek: Chinese PsyOp or an Incredible AI Breakthrough?

There’s a wild conspiracy theory blowing up on X right now and it’s sparking major debates about geopolitics, business, and the future of AI.
The story centers around a company called DeepSeek.
If you haven’t heard, DeepSeek is a Chinese company that’s developed AI models that are rivaling—and in some ways, surpassing—those from American companies like OpenAI, Google, and Meta.
What’s remarkable about this is DeepSeek is achieving this while reportedly spending far less money than its U.S. counterparts.
For example, when the company released DeepSeek-V3 on Christmas day, it claimed that it cost under $6 million to train. For comparison, U.S. companies like OpenAI and Meta spent at least ten times that amount— if not more— to train comparable models.
A few weeks after Christmas, DeepSeek dropped another model, DeepSeek-R1, a powerful reasoning AI model that’s comparable to OpenAI’s o1 model.
And once again, the claim was the same: DeepSeek didn’t need a gigantic budget to achieve its stellar results.
Over the past few days, as it’s become clear what DeepSeek has accomplished, the internet has lit up with debates, speculation, and excitement.
I’m not exaggerating when I say this has completely upended perceptions about the AI industry.
For years, the narrative was that the U.S. was way ahead of China in AI. But suddenly, it’s starting to look like China isn’t just catching up—it’s right there with the U.S., if not ahead in certain areas.
But here’s the big question: Is this story as straightforward as it seems? Or is something else going on behind the scenes?
The DeepSeek Debate
Let me be upfront: I’m not an expert on large language models. But I’ve been digging through analyses from AI experts, and the consensus is that DeepSeek is legit.
They’ve achieved real breakthroughs in training efficiency and model performance.

But while there’s agreement on DeepSeek’s technical prowess, the controversy lies in the cost of its models.
I mentioned earlier that the company claimed that it spent under $6 million training DeepSeek-V3— which is a stunningly low figure that’s well below the cost of similar AI models developed by others.
How did it manage to do that?
One explanation is that necessity leads to innovation: Due to U.S. export controls, DeepSeek hasn’t had access to the full arsenal of cutting-edge hardware, so it’s had to be smarter and more resourceful in its approach.
Remember, the U.S. has restricted exports of the most advanced semiconductor technologies to China, including Nvidia GPUs—the gold standard for training AI models.
Despite this, DeepSeek claims they’ve managed to work around these restrictions and deliver world-class results.
But not everyone believes them.
For example, the CEO of Scale AI, Alexandr Wang, has alleged that DeepSeek has access to over 50,000 Hopper GPUs— a massive quantity of some of the most powerful AI chips designed by Nvidia.
Semiconductor analyst Dylan Patel made similar claims on X, while adding that at least some of the chips may have been acquired by evading sanctions.

This fits with other reports suggesting that Chinese companies have been able to get their hands on restricted U.S. chips despite export controls. If that’s the case, then maybe DeepSeek’s success isn’t as impressive as it seems on the surface.
This blog post by Nathan Lambert, an AI researcher, reaches that conclusion:
“Tracking the compute used for a project just off the final pretraining run [like DeepSeek did] is a very unhelpful [and deceptive] way to estimate actual cost,” he said.
Lambert estimates that DeepSeek’s “cost on compute alone (before anything like electricity) is at least $100M’s per year.”
This skepticism has opened the door to even more speculative theories about DeepSeek’s operations and motivations, like the wild idea that DeepSeek could be part of a psyop— a psychological operation— orchestrated by the Chinese government.
The idea is that China might be exaggerating DeepSeek’s efficiency to raise doubts about the value of building expensive AI infrastructure, with the aim of discouraging U.S. companies from making massive AI investments.
Now, that’s obviously a conspiracy theory; there’s no hard evidence to back it up— but, it’s out there on X.
The conspiracy theorists are in the minority, though. Most AI researchers believe that what DeepSeek has done is noteworthy and a testament to what a talented team can accomplish with fewer resources than the well-funded AI labs in the U.S.
Even Lambert admits that, while the cost of a year of operations for DeepSeek AI is probably “closer to $500M (or even $1B+) [rather than] the $5.5M numbers tossed around,” that’s a success considering they are relevant in an industry where American tech giants are spending “what is approaching or surpassing $10B per year on AI models.”
Why It Matters
The stakes here are enormous. AI is likely to be the defining technology of the next few decades, shaping everything from economic growth to military power. How this race shakes out could have big implications for the balance of power between the U.S. and China, and determine which country emerges as the global leader over the next several decades.
Frankly, I have no idea how this is all going to play out from a geopolitical standpoint.
But I will say that all the panic surrounding DeepSeek kind of reminds me of what happened a couple years ago when China’s largest chip maker, the Semiconductor Manufacturing International Corporation (SMIC), was found to have manufactured 7 nm chips for Huawei.
That discovery shocked the world and triggered a wave of concern about China’s technological capabilities, but upon further inspection, it turned out that the process behind those chips was far less advanced and far more expensive than initially thought.
Is it a similar story in this case? Are people overreacting about DeepSeek the same way they did with SMIC before the full picture emerged?
We’ll find out soon enough.
Is Bigger Always Better?
But this story isn’t just about geopolitics; it’s also challenging long-held assumptions in the technology industry about what it takes to develop cutting edge AI models.
For years, the conventional wisdom was that more computing power translates into more powerful AI models. That’s why companies like Microsoft, Meta, Alphabet and Amazon have collectively spent hundreds of billions of dollars building increasingly powerful computers so they can train these models using enormous amounts of data.
And it’s why Nvidia, the undisputed leader in GPUs—the chips that power these computers—became the world most valuable company in the world in 2024.

There was— and, at least for now, continues to be— an insatiable demand for Nvidia’s AI chips.
But over the past several months, even before DeepSeek arrived on the scene, concerns arose that the “scaling laws”— the idea that more computing power and data leads to more powerful AI capabilities—were reaching their limits.
OpenAI is reportedly finding it more challenging than expected to develop GPT-5, the successor to GPT-4 released in early 2023. The scaling techniques that worked well in the past are now proving less effective at improving model performance.
DeepSeek adds another winkle to this by suggesting that state of the art AI models can be developed with far less computing power than once thought.
Confidence in Scaling Laws
All of this puts Nvidia in an interesting spot. On the one hand, the company is currently benefiting from record-breaking demand for its GPUs. But on the other hand, doubts about scaling laws—and new, cheaper approaches like DeepSeek’s—are creating uncertainty about the longer-term outlook for the company.
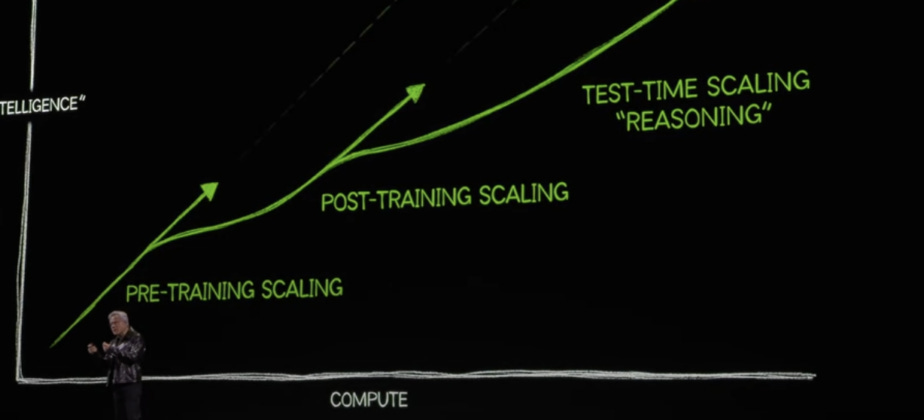
Nvidia’s CEO, Jensen Huang, doesn’t seem worried. He’s argued that while the improvements from pre-training scaling—essentially the gains achieved by making models larger and training them on more data—might be slowing down, they’re not going away.
He’s also said that there are other types of scaling— like post-training scaling and time-test scaling—that can also make AI models more powerful, and that all of these alternative approaches still require significant computing power.
Nvidia’s CEO isn’t alone in thinking that expensive supercomputers will remain essential for driving advancements in AI.
Microsoft has committed to spending $80 billion in capital expenditures this year, up significantly from last year. And Meta came out this week and said it will spend $60-65 billion in capex this year, also a big increase from 2024. Much of that money will go towards gobbling up Nvidia GPUs.
And let’s not forget about the Stargate project— a collaboration between OpenAI, SoftBank, Oracle and MGX—that aims to invest $500 billion in AI infrastructure over the next four years.
All these moves suggest that U.S. tech leaders don’t believe scaling laws have disappeared, which could bode well for Nvidia.

Murky Outlook
That said, things get murkier as we look beyond 2025. Yes, this year will likely be a strong one for Nvidia, fueled by major capex commitments from its biggest customers—a bullish signal.
But what happens after that?
Will the traditional scaling laws continue to hold? And if not, will advancements shift to other dimensions of innovation?
I think it’s highly likely that AI models will keep advancing, one way or another. But who stands to benefit if the approach to improving AI changes?
Nvidia owes much of its success to its dominance in training AI models. But, from what I gather, while it’s still strong, its position in inference—the stage where AI models are deployed to make real-time decisions— isn’t as commanding.
So, if scaling through inference (time-test scaling) is the next frontier of AI innovation, will Nvidia be as successful there? That’s the big question.
In fact, many of Nvidia’s customers have begun designing their own AI chips in collaboration with companies like Broadcom and Marvell because they see an opportunity to gain an edge in inference, where they believe Nvidia’s dominance isn’t as firm as it is in training.
We’ll see what happens with that.
How I’m Thinking About Nvidia
Overall, I think Nvidia is in a strong position, but it’s understandable that investors might feel uneasy given the concerns I’ve outlined—especially following the massive surge in its stock over the past few years.
Since June of last year, Nvidia’s stock has been largely flat as it digests those big gains and investors weigh the sustainability of its growth story.

So, here’s how I’m thinking about Nvidia right now: In the long term—looking 5 to 10 years ahead—I think the stock will do well. It’s led by a visionary CEO, Jensen Huang, and has consistently proven itself to be a highly innovative company operating at the forefront of massive industries.
Whether it be generative AI, autonomous vehicles, or robotics, Nvidia is going to be a big player.
But the short-to-medium term outlook is more uncertain. If we see an AI bubble—I’ve been on the record as saying an AI bubble is very much possible given that most transformative technologies tend to fuel speculative bubbles early on— Nvidia is in prime position to rise with that wave.
On the flip side, if investor enthusiasm for AI starts to cool or concerns about Nvidia’s dominance in the market become more pressing, then then stock could face headwinds.
Nvidia’s profit margins are unusually high right now relative to its own history and that of other big tech companies. I think those margins will eventually normalize, and when that happens, it could act as a drag on the stock.

So, while I like Nvidia long term, I’m not sure about it shorter-term— I can see it going either way. I’m a buyer on big dips, but I wouldn’t be chasing it.
A Boon for Meta
DeepSeek may have complicated Nvidia’s narrative, but I see these new developments as a positive for another area: AI applications.
If the cost of AI dramatically declines, that’s good for companies that are creating products that leverage AI— whether it’s productivity apps that help people work more efficiently, video editing tools that simplify content creation, or generative AI platforms that unlock entirely new creative possibilities.
And one of the biggest beneficiaries of a decline in the cost of artificial intelligence is Meta.
In fact, Meta has been driving for this. The company develops the Llama family of AI models, which, like the DeepSeek models, are open source— meaning anyone can use them for free.
Meta’s goal with Llama isn’t to profit from it— because, after all, it’s free— it’s to drive down costs for the company and ensure that it’s never dependent on proprietary, closed-source models like those from OpenAI.
To the extent the achievements of DeepSeek prove that high-quality AI can be developed at a lower cost, it basically validates Meta’s strategy.
In the long run, a lot of the value in AI is going to come from applications, and Meta is in prime position to benefit from that since it already owns a family of highly-popular social media apps used by billions of people worldwide.
The company has started incorporating AI into its products, making them more engaging for users and useful for advertisers. As AI continues to advance, we’re going to see many more AI capabilities added to these apps, making them even more lucrative for Meta.
Thanks a lot, interesting as always!